Semantic — часть CEDET, унифицированный API в Emacs для работы с исходными текстами. Semantic предоставляет прослойку высокого уровня над низкими процедурами лексического анализа исходников. В составе Semantic есть написанные на Emacs Lisp подобия lex(1) и yacc(1), так что чтобы добавить поддержку нового языка к Semantic, требуется описать его грамматику и определить некоторые специфичные для разбора сорцов на этом языке процедуры (документация по Semantic содержит всю необходимую информацию).
Состав API
На верхнем уровне своего API Semantic позволяет:
Запросить таблицу «тегов» для обрабатываемого файла («тег» в понимании Semantic — «значимый» элемент исходного кода — инклуд, определение функции, произвольный код на нулевом уровне вложенности и т. д.). Для каждого тега извлекается «название», расположение и какая-то дополнительная информация (например, для функций — список аргументов и т. д.)
Из полученной таблицы получить теги определённого типа (функции, глобальные переменные, классы), найти подходящий тег для автодополнения
Много всего другого. Инфраструктура Semantic Database позволяет сохранять результаты обработки не только текущего открытого файла, но и всех, от которых он зависит (заголовочные файлы стандартной библиотеки или просто другие файлы проекта, включённые в рассматриваемый при помощи
#include ".."илиimport ..или(load "..")и т. д.)Семантик позволяет скрывать/показывать тег (aka «folding»), устраивать всякое оформительство, искать теги рядом с курсором и т. д. и т. п.
Информация по указанному содержится в «Semantic Application Development Manual» (есть в дистрибутиве CEDET).
Где применяется
Большинству пользователей не нужно знание Semantic API: на его основе уже написано много полезный расширений для Emacs:
imenu, список тегов текущего файла
senator, высокоуровневая (не «пять строк вниз», а «следующий тег») навигация по тегам
speedbar умеет использовать Semantic для парсинга исходного текста
забавная фича — визуализация тегов текущего файла по сложности (количеству строк). По гистограмме видно, какая функция самая страшная (большая).
хороший комплишен для многих языков (и не просто по текущему буферу, а по включённым в файл, и даже тип переменных умеет показывать (правда, это всё ещё бывает buggy, особенно с не самыми популярными языками))
подсветка ошибочного синтаксиса (того, который не смогли распознать парсеры Semantic для данного языка) — такой облегчённый Flymake (Flymake использует непосредственно компилятор (или другое специальное средство проверки) языка и умеет показывать и более сложные ошибки и предупреждения (необъявленные переменные и прочее))
stickyfunc — когда в видимой части буфера видна лишь «нижняя» часть определения функции без заголовка, этот заголовок показывается в самой верхней строке буфера (сразу видно, чей «хвост» виднеется)
Ввод M-x semantic-load-enable-excessive-code-helpers в Emacs позволяет включить большинство вспомогательных функций для работы с кодом, написанных с помощью Semantic.
Эти штуки значительно помогают разобраться в чужом коде.
В CEDET вообще много плюшек, о существовании которых многие не подозревают — внимательно читаем офсайт.
Чуть более сложное использование инфраструктуры Semantic
(Описываемые дальше тексты программ на Elisp лежат у меня в репо).
Извлечение частей исходных текстов
Недавно мне потребовалось найти решение для такой задачи:
«Вывести на стандартный вывод тело функции с данным именем в данном файле»
В терминах Emacs Lisp с юзанием Семантика она решается так:
(require 'semantic)
;; Return a Semantic tag table for file
(defun get-file-tags (file-name)
(with-current-buffer
(find-file-noselect file-name)
(semantic-fetch-tags)))
;; Return full tag source code (suitable for princ-ing)
(defun get-tag-body (tag)
(let ((from (semantic-tag-start tag))
(to (semantic-tag-end tag))
(buffer (semantic-tag-buffer tag)))
(with-current-buffer buffer
(buffer-substring from to))))
;; Print body of tag with specified name from specified file
(defun print-tag-from-file (tag-name file-name)
(let ((tag-table (get-file-tags file-name)))
(princ (format "%s"
(get-tag-body
(semantic-find-first-tag-by-name
tag-name
tag-table))))))Структура решения понятна: get-file-tags запрашивает список тегов Семантика для обозначенного файла (в Semantic тег представлен простой списочной структурой, работа с которой должна осуществляться через стабильный API), get-tag-body возвращает (строкой) тело тега (в Semantic каждый тег знает, на каких позициях в файле находится его определение), print-tag-body обёртывает эти две функции.
Применяется на практике так (считаем, что grok-lisp.el содержит вышеприведённый код):
$ emacs --batch --load grok-lisp.el \
--exec '(print-tag-from-file "some-tag" "some-source.scm")' \
2> /dev/null(Стандартный поток ошибок stderr специально перенаправляется в пустоту: в Emacs функция princ, используемая в решении, при запуске в пакетном режиме (--batch) печатает свой аргумент на стандартный вывод stdout, а на stderr плюётся функция message, при помощи которой Emacs может выводить статусные сообщения при загрузке файла или подключении библиотеки; например, у меня печатается такое:
!! File eieio uses old-style backquotes !!
Loading vc-hg...Перенаправление 2> /dev/null удаляет из вывода консольной команды статусные высеры Емакса, не оставляя там ничего, кроме запрошенного тела функции.)
Забавно, что print-tag-from-file нормально работает со многими языками (тестировал с Elisp, Scheme, C, Python), а его реализация не содержит упоминаний хотя бы одного из них.
Построение графа зависимостей между функциями
Удивительно, но я не нашёл ни одной рисовалки зависимостей функций для сорцов на Scheme. Было бы интересно решить эту задачу при помощи Семантика (надеюсь, где-то всё-таки есть более продвинутый генератор графов зависимостей).
Прежде всего, условимся считать функцию f зависящей от g, если в теле f упоминается символ g. Это дико провокационная формулировка, не учитывающая некоторые поганенькие подробности. Например, глобальный биндинг функции g может быть перекрыт совершенно левым локальным g; функция f будет упоминать g, но не являться зависящей от той самой функции g из глобальной области видимости, которую мы имеем в виду:
(define (g x) (* x x))
(define (f x)
(let ((g 5))
(+ g x)))или так:
(define (g x) 5)
(define (f x)
(define (g x) (/ x 2))
(+ 10 (g x)))Решение задачи в общем виде для произвольного языка (в смысле, для хотя бы нескольких одновременно) нетривиально.
У меня всё было проще — есть пяток файлов с маленькими функциями, надо нарисовать между ними грамотно стрелочки.
Задача разбивается на несколько частей.
Нужно получить список всех функций в нужном файле. Кроме того, файл может использовать функции из других подгружаемых файлов (например, в Scheme я пишу (load "shared.scm") и использую функции оттуда) — их тоже нужно запросить.
(require 'semantic)
(require 'semanticdb)
(semanticdb-toggle-global-mode)
;; Get a list of all 'function tags declared in specified file and its
;; included files
(defun get-file-functions-deep (file-name)
(with-current-buffer
(find-file-noselect file-name)
(semanticdb-strip-find-results
(semanticdb-find-tags-by-class
'function))))Теперь нужно обработать целиком определение какого-то тега и найти в нём вхождения других. Обычный поиск по тексту не подойдёт, лучше использовать предоставляемый Семантиком лексер — через функцию semantic-lex. Тогда легко видеть, что вот такая функция делает что надо:
;; Return a list of tags from tag-table which are also mentioned in
;; tag
(defun get-tag-deps (tag tag-table)
(let ((from (semantic-tag-start tag))
(to (semantic-tag-end tag))
(buffer (semantic-tag-buffer tag))
;; Build associative list with tag names as keys
(deps (mapcar
(lambda (tag)
(cons (semantic-tag-name tag)
tag))
tag-table)))
(with-current-buffer buffer
(let (result)
;; cddddr is a Lisp-oriented hack to prevent tag itself from
;; inclusion to dependency list
(dolist (lexem (cddddr (semantic-lex from to 1.0e+INF)) result)
(if (eq 'symbol (car lexem))
(let* ((lexem-string (buffer-substring
(cadr lexem)
(cddr lexem)))
(found-tag (assoc lexem-string
deps)))
(if found-tag
(add-to-list 'result (cdr found-tag) t)))))))))Эта функция принимает два параметра — тег Семантика и таблицу тегов, которые предполагается искать в первом (обёртка над этой функцией, формирующая два нужных аргумента tag и tag-table, будет описана далее).
Дальше строится ассоциативный массив из tag-table, где ключами являются метки искомых в функции тегов.
После этого при помощи (semantic-lex from to 1.0e+INF) строится список из лексем в теле функции, из них выбираются те, которые имеют тип 'symbol (для Лиспов это так) и присутствуют в таблице искомых тегов. Число 1.0e+INF, как ни странно, обозначает бесконечность, а вызов semantic-lex с таким аргументом означает парсинг без ограничения на (глубину (вложенности (блока))). Если в обрабатываемой функции встретился искомый символ, он добавляется к списку result, который является возвращаемым из get-tag-deps значением.
Функцию get-tag-deps невозможно ещё использовать, понадобится ещё обёртка:
;; Return a list of pairs (TAG . DEPS) where DEPS is a list of
;; functions TAG «depends» on
(defun get-file-depgraph (file-name)
(interactive "fFile name: ")
(let ((deep-tag-table (get-file-functions-deep file-name))
(file-tag-table (get-file-functions file-name))
(depgraph))
(dolist (tag file-tag-table depgraph)
(let ((deps (get-tag-deps tag deep-tag-table)))
(add-to-list 'depgraph (cons tag deps) t)))))Которая строит список зависимостей не для одной данной функции, а для всех в указанном файле, возвращая список следующей структуры:
((TAG1 . DEPS1) (TAG2 . DEPS2) .. (TAGN . DEPSN))Где DEPS — тоже списки из тегов; очевидно, что множество первых элементов пар является подмножеством вторых элементов (так как функция может «зависеть» от функций, объявленных в другом файле).
Осталось написать ещё одну обёртку, которая будет действовать уже на уровне списка файлов, выводя на печать описание графа зависимостей между функциями в формате dot (возможно, правильнее было бы использовать высокоуровневую систему eieio (аналог CLOS для Elisp), а из описаний в её терминах уже генерить текстовый вывод в различных форматах, но dot — это тоже очень переносимый и широко используемый формат для описания графов):
;; Print depgraph for functions in specified files in DOT format
;; (suitable for processing with Graphviz programs)
(defun print-files-depgraph (&rest file-names)
(princ "digraph D {\n")
(princ "overlap=scale;\n")
(dolist (file file-names)
(let ((depgraph (get-file-depgraph file)))
(dolist (dep-list-for-tag depgraph)
(let ((function-name (semantic-tag-name
(car dep-list-for-tag))))
(princ (format "\"%s\";\n" function-name))
(dolist (dependency (cdr dep-list-for-tag))
(princ (format "\"%s\" -> \"%s\";\n"
(semantic-tag-name dependency)
function-name)))))))
(princ "}\n"))Эта функция вкладывает несколько отображений разных списков друг в друга: в каждом файле из переданного ей списка для каждой зависимости каждой функции этого файла (почти сошёл с ума, пока писал эту конструкцию со словами «каждый» :-) выводит строку вида "function" -> "dependency".
В предположении, что весь вышеперечисленный код содержится в файле grok-lisp.el, можно попробовать использовать его для генерации графа зависимостей между функциям в файле на каком-нибудь Лиспе. Например, в том же grok-lisp.el :-)
$ emacs --batch --load grok-lisp.el \
--exec '(print-files-depgraph "grok-lisp.el")' \
2> /dev/null \
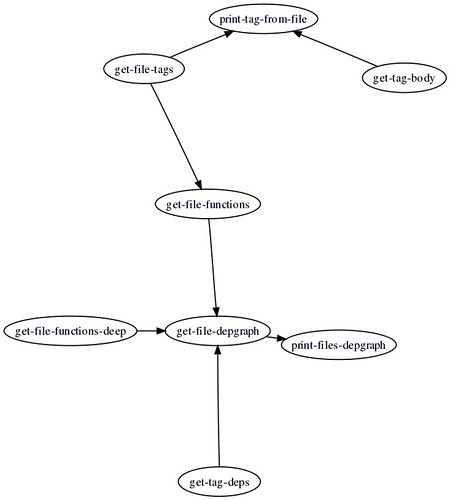
> grok-lisp.dotЗаглянув в полученных файл, увидим:
digraph D {
overlap=scale;
"get-file-tags";
"get-tag-body";
"get-tag-deps";
"print-tag-from-file";
"get-file-tags" -> "print-tag-from-file";
"get-tag-body" -> "print-tag-from-file";
"get-file-functions";
"get-file-tags" -> "get-file-functions";
"get-file-functions-deep";
"get-file-depgraph";
"get-file-functions-deep" -> "get-file-depgraph";
"get-file-functions" -> "get-file-depgraph";
"get-tag-deps" -> "get-file-depgraph";
"print-files-depgraph";
"get-file-depgraph" -> "print-files-depgraph";
}Теперь любой программой из Graphviz можно сгенерировать изображение:
$ fdp -Tpng -O grok-lisp.dotА вот и получившийся граф:
Эта программа уже не работает, скажем, с исходниками на C. Например, придётся к списку возможных типов лексемы в get-tag-deps добавлять 'NAME, потому что Semantic использует для сишных сорцов именно такое обозначение (а не 'symbol, как для Лиспов). Кроме того, может понадобиться изменять режим обработки semanticdb включаемых в сорец файлов. Мне к примеру, более интересно смотреть лексические зависимости между теми функциями, которые написал я, а не то, сколько функций libc для работы со строками упоминает код (можно их считать элементарными операциями).
Описанный код также подавится, если в нескольких файла встречается функция с одним и тем же именем :-)
eieio содержит программку call-tree, которая позволяет генерировать графы вызовов для функций на Elisp; рассмотренное выше решение, однако, занимается созданием графов простой лексической зависимости между функциями. Я успешно применял print-files-depgraph и для генерации развесистой клюквы из программ на Scheme.
Использование dot в качестве выходного формата позволяет использовать graph(3) для обработки программы (из графа зависимостей, очевидно, можно узнать очень многое; хотя бы уже один взгляд на граф программы даёт возможность оценить её структуру, связность и другое).